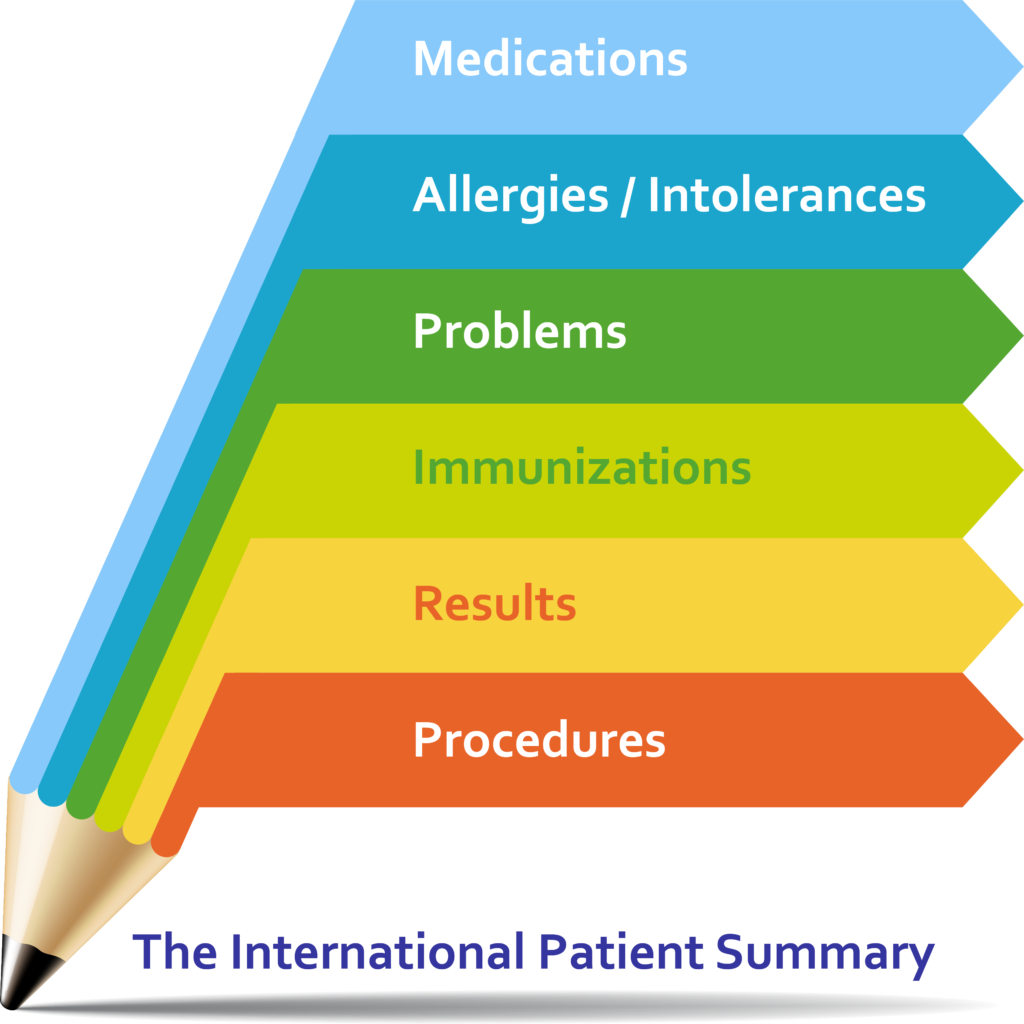
The International Patient Summary is a minimal and non-exhaustive set of basic clinical data of a patient, specialty-agnostic, condition-independent, but readily usable by all clinicians for the unscheduled (cross-border) patient care.
About Patient Summaries
A Patient Summary is a standardized set of basic clinical data that includes the most important health and care related facts required to ensure safe and secure healthcare.
This summarized version of the patient’s clinical data gives health professionals the essential information they need to provide care in the case of an unexpected or unscheduled medical situation (e. g. emergency or accident).
While this data is mainly intended to aid health professionals in providing unscheduled care, it can also be used to provide planned medical care, e. g. in the case of citizen movements or cross-organizational care paths, or even as a crystallization point for health records.
Latest on IPS
-
More multimedia and IPS-athon
We have added multimedia to our website, including a video on the IPS-athon in New Zealand. Read more…
-
IHE publishes the Sharing of IPS (sIPS) Profile
IHE has added a profile to the IPS standards and specifications, which is a welcome addition to support both publication and on-demand access to an IPS. Read more…